

We’ve updated the very popular blog titled, “The Best Data Ingestion Tools for Migrating to a Hadoop Data Lake” in 2022.
by Mark Sontz –
The world’s most valuable resource is no longer oil, it’s data. Data in its raw form is valuable, but it needs to be processed to be usable, and be timely and reliable. Making quality data available in a reliable manner is a major success factor for any data analytics initiative. Data engineering teams are being asked to deliver quality data in less time. The ability to ingest, process and deliver data in real-time is becoming a necessity for business insight and informed decision-making. As organizations are collecting and analyzing vast amounts of data, traditional on-premise solutions for data ingestion, storage, management and analytics can no longer keep pace.
Modern Data Platforms in the Cloud
The promise of achieving significant, measurable business value from data can only be realized if organizations put into place a scalable and extensible modern data platform. When you think of scalability and extensibility these days, you naturally think of the cloud. The benefits of the cloud include greater flexibility, scalability, and cost-efficiency, among other benefits.
But there are myriad options whether it be native services provided by the cloud service providers, third party applications and platforms, or SaaS solutions. Architecturally, data platform thinking has come a long way from relational database management systems that had a dominant footprint on-premise and in the cloud alike. Of note are Hadoop, NoSQL databases, and the paradigm of separating storage from data structure/organization (or schema) altogether. Hadoop opened the doors to ingesting data in any form, whether structured, semi-structured or unstructured, and subsystems like Hive started the trend of separating storage from schema. Hadoop has, however, declined in popularity with the advent of better technology options, and is considered legacy these days. NoSQL (which stands for Not Only SQL) covers a broad range of options ranging from columnar to document to graph databases to name a few, each of which is useful for certain types of data storage, analysis, and delivery requirements. The paradigm of separating storage from schema is a relatively new one; it is gaining traction and is becoming more aligned with microservices- and API-driven principles that have a proven track record in modern and cloud-based application development.
Below is a brief description of what’s available from the big 3 cloud service providers Amazon, Microsoft, and Google, each of whom offer (quasi-)relational, Hadoop-oriented, NoSQL and storage/schema separation options. In addition, Databricks, Cloudera and Snowflake provide cloud-based modern data platforms.
Amazon Web Services:
Along with many different native services such as S3, Redshift, QuickSight and Athena which can be integrated to provide a custom solution, AWS offers Lake Formation1 that automatically configures the core AWS services necessary to tag, search, share, transform, analyze, and govern specific subsets of data across a company or with other external users.
Microsoft Azure:
Microsoft provides a host of native services which includes all the capabilities required to make it easy for developers, data scientists, and analysts to ingest, store data of any size, shape, and speed, and do all types of processing and analytics across Microsoft platforms and languages. These services include Event Hubs, Data Factory2, Data Lake Storage, Synapse, Analysis Services.
Google:
Google offers a fully managed enterprise data warehouse for analytics with its BigQuery3 product. The solution is serverless and enables organizations to analyze any data by creating a logical data warehouse over managed, columnar storage, and data from object storage and spreadsheets. BigQuery captures data in real-time using a streaming ingestion feature, and it’s built atop the Google Cloud Platform. The product also provides users the ability to share insights via datasets, queries, spreadsheets, and reports.
Databricks:
Databricks offers a cloud and Apache Spark-based platform that combines data engineering and data science functionality. They call this a “lakehouse”, the data lakehouse is a data management architecture that combines the best of data warehouses and data lakes on one platform. This architecture centers around Delta Lake4 which includes proprietary features for operationalization, performance, and real-time enablement on AWS, Azure or GCP.
Cloudera:
The Cloudera Data Platform (CDP)5 manages and secures the data lifecycle across all major public clouds and the private cloud. The product optimizes workloads based on analytics and machine learning, enables users to view data lineage across any cloud and transient clusters, and features a single pane of glass across hybrid and multi-cloud environments. CDP can scale to petabytes of data and thousands of diverse users.
Snowflake:
Snowflake6 offers a cloud data platform which spans the 3 major cloud providers. As a fully managed service, the platform requires near-zero maintenance and no infrastructure. Snowflake provides one platform which allows many workloads to process one copy of data. The solution architecture allows unlimited performance and scalability.
Where to Begin
Once you have decided to migrate to a cloud-based data platform, RCG’s data platform reference architecture depicted below provides the framework for determining your requirements, enabling proper data processing and management capabilities, and selecting the correct technologies to match your needs.
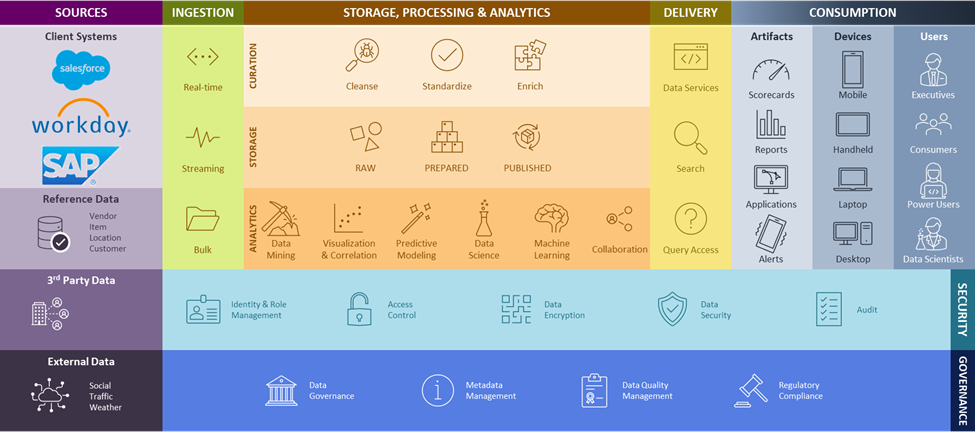
Let’s look at some of the tools available for ingesting data into the cloud data platform or other raw cloud storage.
RCG|enable™ Data
RCG|enable™ Data is our Data Ingestion Framework which is a fully integrated, highly scalable, distributed and secure solution for managing, preparing and delivering data from a vast array of sources including: social media, mobile devices, smart devices and enterprise systems.
The framework is vendor-agnostic and supports data sources (structured, semi-structured and unstructured) and targets in traditional enterprise systems, external systems, and the 3 cloud service providers. The framework is also a Cloudera-validated solution.
The RCG|enable™ Data service and framework eliminates the need for IT professionals to become experts in cloud-native ecosystem technologies, and speeds time-to-delivery at reduced costs by simplifying and standardizing data management and data workflows.
Other Tools
The following are currently some of the other most popular tools for the job:
StreamSets Data Collector8 (SDC) and Transformer
With StreamSets you can build, run, monitor, and manage smart data pipelines at scale. StreamSets takes a record-based approach. It’s schema-on-read approach for pipelines (whether it’s JSON, CSV, etc.) parses data into a common format. This means that the responsibility of understanding the data format is no longer placed on each individual processor, and so any processor can be connected to any other processor. Their large number of connectors and processors provides strong SDC integration with multi-cloud, hybrid, and Hadoop architectures. SDC executes using a proprietary processing engine, while Transformer leverages Apache Spark.
Apache Kafka (Confluent9, Amazon MSK, Azure Event Hubs, Google Pub/Sub)
Kafka is a highly scalable distributed event streaming platform. At its heart is an immutable commit log, producers publish messages on Kafka topics, and consumers subscribe to topics and use the data from them as they please. Unlike traditional messaging queues, Kafka is a highly scalable, fault-tolerant distributed system, allowing it to be deployed for applications like those providing real-time analytics.
Snowpipe
If you base your data platform on Snowflake, then you will most undoubtably want to look at Snowpipe7. Snowpipe is used to load data from files as soon as they are available in a defined staging area. Data can be loaded in micro-batches, making it available to users within minutes or in bulk depending on your needs. Automated data loads can be established by leveraging event notifications for cloud storage to inform Snowpipe of the arrival of new data files to load. Snowpipe then copies the files into a queue, from which they are loaded into the target table in a continuous, serverless fashion.
AWS Glue
Glue10 is a serverless data integration service to prepare data for analytics. With Glue you define your ETL jobs using a graphical drag-and-drop interface which generates code to extract, transform, and load your data. The code is generated in Scala or Python and written to execute on Apache Spark. For an event-driven process, you can set up a Lambda function to trigger ETL jobs which will execute as soon as new data becomes available in S3.
Azure Data Factory
Data Factory is Microsoft’s serverless data integration service, similar to Glue. The difference is Data factory utilizes compute services such as HDInsight Hadoop, Azure Databricks, and SSIS runtime on Azure SQL Database.
Google Cloud Dataflow
Cloud Dataflow is a fully managed service for processing large datasets using Apache Beam pipelines. Dataflow is also serverless and capable of performing stream or batch processing.
Ask the right questions …
As you get started, it’s important to first answer a few key questions about your environments and your needs:
- What kind of data will you be dealing with (internal/external, structured/unstructured, operational, PII/NPI, etc.)?
- Who are the key consumers of the data, including external consumers?
- What business outcomes do you hope to achieve?
- What is your existing data management architecture?
- Who is going to be the steward of the data?
But the most important question to ask is this: Do we have the in-house skill set and are we otherwise organizationally ready to successfully carry out this migration? Providing an honest answer to that question, and acting accordingly, will lay the foundation for a successful buildout of a modern data platform in the cloud.
Works Cited
1. AWS "AWS Lake Formation" https://aws.amazon.com/lake-formation/?whats-new-cards.sort-by=item.additionalFields.postDateTime&whats-new-cards.sort-order=desc
2. Azure Data Factory https://azure.microsoft.com/en-us/products/data-factory/
3. Google Cloud https://cloud.google.com/bigquery
4. Delta Lake on Databricks Demo https://www.databricks.com/discover/demos/delta-lake#account
5. Cloudera Data Platform (CDP) https://www.cloudera.com/products/cloudera-data-platform.html
6. Snowflake https://www.snowflake.com/en/
7. Snowflake "Getting Started with Snowpipe" https://quickstarts.snowflake.com/guide/getting_started_with_snowpipe/index.html#0
8. StreamSets Data Collector https://docs.streamsets.com/sdk/latest/api/sdc_api.html
9. Confluent https://www.confluent.io/
10. AWS Glue https://aws.amazon.com/glue/